이번 포스트에는 조건부 GAN 인 CGAN에 대해 공부해보자.
파이토치로 구현한 코드는 아래의 링크로 들어가보면 참고할 수 있다.
https://github.com/BySanghyeon/AI_Paper_Review/blob/main/GAN/CGAN.ipynb
Abstract
이 연구는 기존의 GAN의 조건부 버전인 CGAN을 소개한다.
이는 discriminator와 generator 둘 모두에 조건을 부여하고 데이터를 입력하면 된다.
이 모델을 multi-modal model을 학습하는데 어떻게 사용되는지 설명한다. 그리고 이 방법이 어떻게 training label에 포함되지 않은 설명 태그를 생성하는 image tagging의 예시를 제공한다.
1.Introduction
GAN은 생성 모델의 많은 확률적 연산 과정을 확인할 수 없는 어려움을 해결하기 위한 대체 프레임워크로 소개되었다. GAN은 Marvov chain을 사용하지 않고 온전히 backpropagation만을 이용해 기울기를 얻을 수 있다. 이와 더불어 학습 동안 추정이 필요 없고, 다양한 요인과 상호작용이 이 모델에 손쉽게 포함시킬 수 있다. 조건부가 없는 GAN은 생성된 데이터의 모드를 통제할 수 없다. 하지만 조건을 부여함으로써, data generation process를 통제할 수 있다. 그러한 조건은 class label이나, data의 일부분, 혹은 다른 modality의 데이터에 기반을 둘 수 있다. 이 연구에서 CGAN을 어떻게 구현했지는 지 알 수 있다. 그리고 MNIST digit 데이터에서 class label에 조건을 건 실험과, MIR Flickr 25,000 데이터를 활용한 multi-modal leanrning과 관련한 실험 결과를 보여준다.
2. Related Work
2.1 Multi-modal learning for Image Labelling
많은 지도 신경망 모델들의 성공에도 불구하고 여전히 몇몇 한계점이 존재한다. 첫 번째, 방대한 양의 예측된 출력 범주를 수용하기 위해 모델을 확장하는 데 어려움이 있다. 두 번째, 현재까지 많은 연구가 입력부터 출력까지 one-to-one 매핑에 초점이 맞춰져 있었다. 하지만 많은 흥미로운 문제는 one-to-many 매핑과 관련이 있다. 예를 들어 이미지 라벨링의 경우, 주어진 이미지에 적절한 다른 태그들을 부여할 수도 있고, 사람에 따라 똑같은 이미지를 다른 용어로 설명할 수도 있을 것이다.
앞선 언급한 첫 번째 문제를 해결하기 위한 한 방법으로는 다른 모달리티로부터 추가적인 정보를 활용하는 것이다. 예를 둘오 지리적인 관계에 대한 라벨을 위해 자연어 말뭉치를 이용해 벡터 표현을 학습하는 것은 매유 의미가 있을 것이다. 그러한 공간에서 예측을 할 때, 예측에 에러가 있다고 해도 여전히 우리의 예측인 사실에 근사하다는 이점이 있다. 그리고 또한 학습 동안 보지 뭐 했던 라벨에 대해 자연스럽게 예측적인 일반화를 한다는 이점도 있다.
두 번째 문제를 해결하기 위한 방법은, 조건부확률 생성 모델을 사용하는 것이다. 이는 입력이 조건을 부여하는 변수이고 one-to-many 매핑을 conditional predictive distribution로서 예로 들 수 있다.
3. Conditional Adversarial Nets
3.1 Generaive Adversarial Nets
GAN에는 Generator와 Discriminator 두 가지 adversarial 모델이 있다. 자세한 내용은 이전에 GAN 리뷰에서 다뤘으니 아래의 링크를 따라 해당 포스트를 참고하면 된다.
[논문리뷰]Generative Adversarial Nets
Abstract 이 논문에서는 적대적 과정을 통해 생성 모델을 예측하는 새로운 프레임워크를 소개한다. 이 적대적 과정은 데이터의 분포를 저장하는 생성 모델 $G$와 $G$의 데이터가 아닌 학습 데이터
dream-be.tistory.com
3.2 Conditional Adversarial Nets
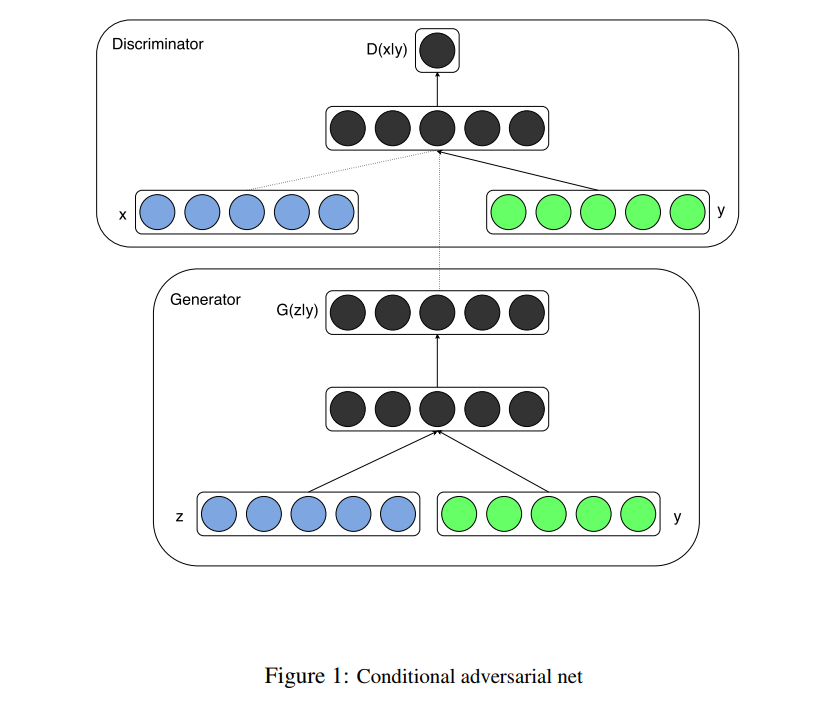
만약, 어떤 추가적인 정보 $y$에 대해 generator와 discriminator에 조건을 부여하면, GAN은 conditional GAN으로 확장될 수 있다. $y$는 클래스 라벨, 다른 모달리티의 데이터 등 아무 종류의 보조적인 정보일 수 있다. generator와 discriminator 둘 모두에게 $y$를 추가적인 입력 레이어로 더해 줌으로써 조건을 부여할 수 있다.
Generator에서 사전 입력 노이즈 $P_z(z)$와 $y$는 hidden representation 안에서 결합된다. 그리고 adversarial training framework는 어떻게 이 hidden representation이 이뤄졌는지에 대해 상당히 유연하게 감안한다.
Discriminator에서는 $x$와 $y$는 입력으로 discriminative 함수에 들어간다.
4. Experimental Results
4.1 Unimodal
MNIST 이미지의 원학 벡터로 인코딩된 class label에 조건을 걸어 CGAN을 학습했다.
G에서 100차원의 $z$ 이전의 노이즈는 unit hypercube 내의 uniform distribution으로부터 추출됐다. $z$와 $y$는 둘 다 결합된 1200 차원의 나 hidden ReLU 레이더로 매핑되기 전에, 사이즈 200의 hidden layer와 사이즈 1000의 ReLU 함수에 매핑되었다. 그리고 최종적으로 784차원의 MNIST 샘플을 생성하기 위한 출력으로 sigmoid unit 함수가 있다.
D는 $x$를 240 유닛과 5조각으로 된 maxout 레이어에 매핑하고 $y$는 50유닛과 5조각으로 된 maxout 레이어 매핑한다. s도 hidden 레이어 둘 다 sigmoid 레이어를 거치기 전에 240유닛과 4조각으로 된 joint maxout 레이어에 매핑된다.
모델은 미니 배치 사이즈를 100으로 설정한 SGD를 이용하여 학습했다. 초기 learning rate는 0.1로 설정하고 1.0000 decay factor를 가지고 지수적으로 0.000001까지 감소된다. 또한 모멘텀은 초깃값으로 0.5로 시작하여 0.7까지 증가한다. Dropout은 0.5 확률을 가지고 G와 D 모두에 적용한다. 그리고 검증 세트에 대한 가장 뛰어난 성능의 log-likelihood를 stopping point 롤 사용했다.
CGAN의 결과는 다른 모델들과 비교할 수 있지만 성능이 더 좋은 몇몇의 다른 접근법이 있다. 여기에는 GAN도 포함된다. 이 연구의 결과는 모델의 효과보다는 POC(proof of concept: 본 연구진의 사전 연구라고 생각하면 이해가 쉽다.)와 조금 더 가깝다
4.2 Multimodal
사용자 생성 메타데이터(User-generated metadata:UGM)는 표준이 되는 이미지 라벨링과는 다르다. 왜냐하면 이들은 설명이 더 자세하고, 단순히 이미지 안의 객체를 인식하는 것이 아니라 의미적으로 인간들이 이미지를 묘사하는 방식과 훨씬 더 가깝기 때문이다. UGM의 또 다른 특성은 동의어가 일반적이고 다른 사용자들은 동일한 개념에 대해 설명하기 위해 다른 단어들을 사용할지도 모른다. 결과적으로, 이러한 라벨들을 효율적으로 정규화하는 방법을 확보하는 것이 중요하다. 개념적인 단어인 베딩은 관련된 개념이 비슷한 벡터에 의해 표현되기 때문에 굉장히 중요하다.
여기서, CGAN을 이용해서 image feature에 대한 tag-vectors 조건부 분포를 생성하는 자동화된 이미지 태깅에 대해 보여준다.
Image feature를 위해 연구팀은 21,000개의 라벨을 가진 ImageNet 데이터를 사용한 모델과 비슷한 CNN 모델을 사전 학습한다. 그리고 마지막 fully connected 레이어의 4096 유닛의 출력을 image representation으로 사용한다.
word representation을 위해 YFCC100M 데이터 셋의 메타 데이 데이터에서 사용자 태그, 제목, 설명을 합친 말뭉치를 수집했다. 텍스트를 전처리한 후 word vector 사이즈 200으로 skip-gram 모델을 학습했다. 그리고 200번 이하로 등장하는 단어들은 제외 시 칸 총 247,465개의 단어를 가진 단어사전을 마련했다.
실험을 위해서 MIR Flickr 25,000 데이터 셋을 이용했다. 그리고 앞선 언급한 CNN 모델과 language model을 이용해서 이미지와 태그 feature들을 추출했다. 태그가 없는 이미지들은 제외했고 annotation들은 추가적인 태그로 처리했다. 처음 15만 개개를 학습 셋을 이용했다. 다수의 태그가 있는 이미지들은 각각의 태그마다 학습 세트에서 반복되었다.
평가를 위해서 각각의 이미지마다 100개의 샘플을 생성하고 각 샘플마다 코사인 유사도 가 제일 높은 20개의 단어를 정리했다. 그리고 100개의 샘플 중에서 가장 흔한 10개의 단어를 선택했다.
가장 성능이 좋은 모델의 G는 사이즈 100의 가우에 안 노이즈를 먼저 받고 이른 500차원의 ReLU 레이어에 매핑한다. 그리고 4096 차원의 이미지 피처 벡터를 2000차원의 2000차원의 ReLU hidden layer에 매핑한다. 이 레이어들은 생성된 워드 벡터들을 출력으로 반환하는 200 차원의 결합된 선형 레이어에 매핑된다.
하이퍼 파라미터와 구조는 cross-validation과 random grid search와 manual selectio의 조합을 통해 결정됐다.
5. Future Work
이 연구의 결과는 굉장히 초기 단계에 가깝다. 하지만 CGAN의 잠재력을 증명했고 유용한 활용방안들이 있을 것으로 보인다.
현재의 연구에서는 각각의 태그를 개별적으로 사용했다. 하지만 다수의 태그를 동시에 사용해서 더 나은 결과를 얻을 수 있을 것으로 예상된다.
또한 language 모델을 학습하기 위해 결합 학습 방안을 구성하는 것도 앞으로 추가적인 연구의 방향이 될 수 있다고 생각한다.
'AI' 카테고리의 다른 글
| [파이토치]자동미분_AUTOGRAD (0) | 2022.09.30 |
|---|---|
| [파이토치]신경망 구성 (0) | 2022.09.29 |
| [파이토치] Transform (1) | 2022.09.21 |
| [논문리뷰]Attention Is All You Need (1) | 2022.09.20 |
| [PyTorch]Dataset과 DataLoader (1) | 2022.09.16 |




댓글